 Skip to content
Skip to content

Data is an integral part of modern business processes. The generation, processing, storage and utilization of data is an important part of a data driven business. However, the various data sources and processing tools make it often difficult to achieve holistic data management processes. Especially in R&D good data management can decide between failure and success. Unfortunately, data management in R&D is also particularly difficult as data sources may include production, research, human generated and business related data. To unify these data streams into tidy data sets is very challenging.
xT SAAM follows tidy data management guidelines, which makes the generation, processing, storage and utilization of data easier than ever. In general, xT SAAM has two main ways of data generation. In passive data generation mode xT SAAM receives existing or externally generated data sets from production systems, databases, manual input and more. These data sets are then converted into data matrices that follow tidy data management guidelines.
The second mode of operation is in active data generation mode. Here data is generated in a Design of Experiments like process in cooperation between user, machine and xT SAAM. The workflow and GUI of xT SAAM requires the user to follow tidy data management guidelines, which in return produces clean data sets for further processing.
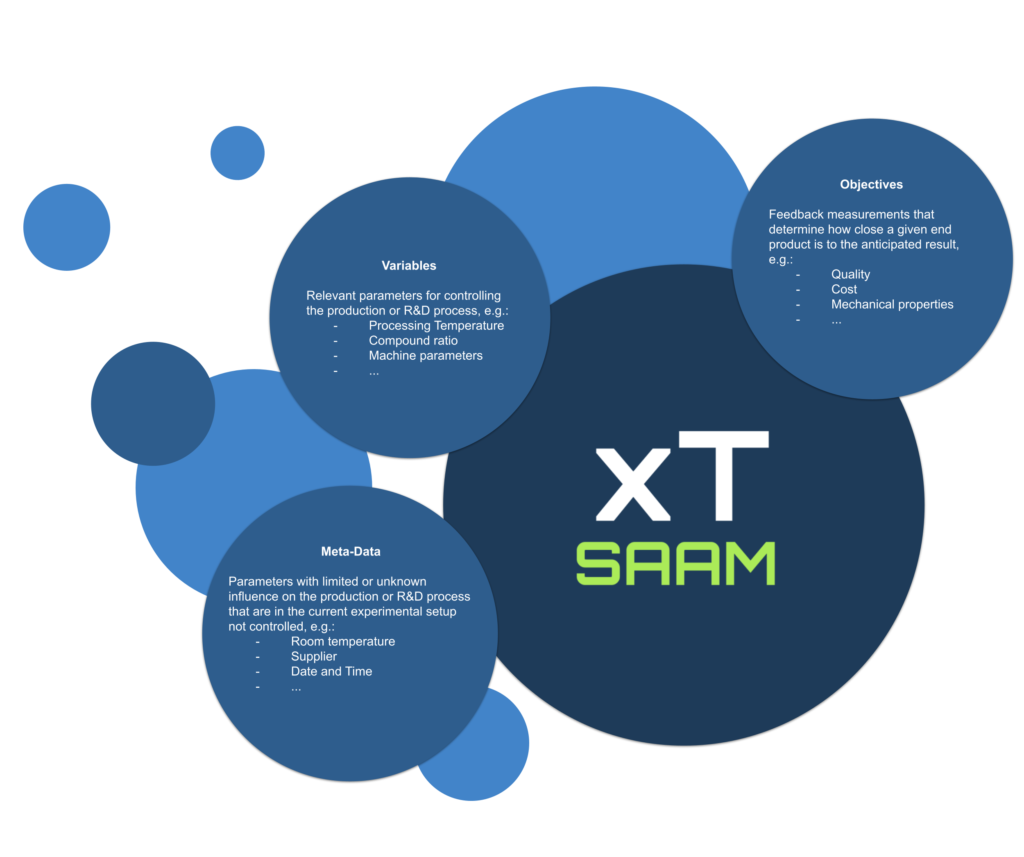
The data sets for xT SAAM consist of 3 types of external data types. Variables, objectives and metadata (for more info see Fig. 1). These data types describe objective reality of the given system. Within xT SAAM the data sets can be further enriched by adding functional relations between data, developing models and generating synthetic data points. The enriched data is then as well stored in tidy data format together with the initial data sets.
Due to the clean way of data storage additional data can be added at any time to each data set in case necessary, new findings can be verified on existing data and corrections can be made to the original data sets. Additionally, all data is characterized, searchable and programmable, which allows the reuse of existing data sets in new R&D projects.
For our customer this means:
- Less cost and effort in the data management
- More value from generated data
- Easier knowledge and succession management
- Generate meaningful models from small data sets
If this article got you interested, contact us at info@x-t.ai